
阅读提醒:将本文结合源码一起使用味道更佳哦!~
前言
LinkedList在很多源码中被广泛的使用。大家常将它与ArrayList做对比,二者不论是从数据结构还是实现逻辑上都很大的差异。希望通过本文能让大家在类似需要线性存储数据的场景下能更好的选择适应容器。
类定义
1 | public class LinkedList<E> |
AbstractSequentialList:AbstractList的子类(ArrayList也是其子类之一),实现一些基本的get/add方法,不过很多方法被已经被LinkedList复写。
Deque:双端队列,即可以选择从头部或者从尾部进行数据操作
Cloneable:标记接口,声明LinkedList重写clone方法。这里LinkedList实现的是浅拷贝,即复制内部链表元素
Serializable:标记接口,可被默认的序列化机制序列化与反序列化
主要内容
数据结构
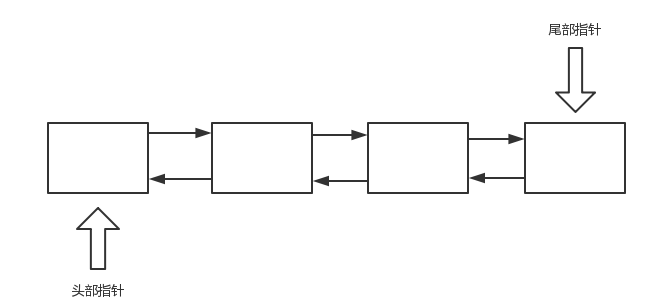
ArrayList由数组实现,因此需要整块连续的内存。而LinkedList底层是由双向链表实现,元素之间可以处在不同内存区域。互相只需要持有对方的引用,因此不需要连续的内存,能充分利用一下较小的碎片内存,这是其优点之一。
1 | transient int size = 0; //链表的长度 |
LinkedList的数据结构很简单。只有以上三个变量。
- 链表的长度;
- 指向第一个元素的指针;
- 指向最后一个元素的指针;
需要注意的是LinkedList里的Node节点是双向节点,即可以知道杀上一个和下一个节点。这里和HashMap的单向节点是有区别的。双向节点的作用是可以从任意一个方向进行变量,从头到尾,还是从尾到头。
transient这个关键字,之前在ArrayList中讲过,就是在序列化的时候,不将此元素加入序列化内容中。
其结构相当于这样
数据操作
LinkedList的在插入和删除方面几乎都是围绕着一件事情
节点间关系的建立(插入)与重建(删除)
插入
linkedList的插入分为头部插入、尾部插入和指定位置插入,我们先说说头部插入和尾部插入:
头部插入:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15public void addFirst(E e) {
linkFirst(e);
}
private void linkFirst(E e) {
final Node<E> f = first; //通过first引用,获取第一个元素节点f
final Node<E> newNode = new Node<>(null, e, f); //将元素包装为一个节点newNode,它的下一个元素是f
first = newNode; //将first引用改为新生成的节点
if (f == null) //如果第一个节点为空,说明当前的链表只有一个元素,所以尾元素也是newNode
last = newNode;
else
f.prev = newNode; //如果现在链表有存在2个以上的元素,则将f的前一个节点设置为newNode
size++;
modCount++;
}
以上的代码比较简单,总体就是两个部分
- 将当前first引用的节点与新生成的节点互相建立绑定,新生成的节点在前;
- 将头部指针(first)指向新生成的节点;
尾插法的流程和头插法及其类似,也是两个部分
- 将当前last引用的节点与新生成的节点互相建立绑定,新生成的节点在后;
- 将头部指针(last)指向新生成的节点;
我们这里再看看尾插法的代码加深一下印象:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15public void addLast(E e) {
linkLast(e);
}
void linkLast(E e) {
final Node<E> l = last; //1. 通过last引用,获取第一个元素节点l
final Node<E> newNode = new Node<>(l, e, null); //2. 将元素包装为一个节点newNode,它的上一个元素是l
last = newNode; //将last引用改为新生成的节点
if (l == null) //如果第一个最后为空,说明当前的链表只有一个元素,所以头元素也是newNode
first = newNode;
else
l.next = newNode; //如果现在链表有存在2个以上的元素,则将l的后一个节点设置为newNode
size++;
modCount++;
}
无论是头插法或者是尾插法都时间复杂度是O(1),而接下来要说的指定位置插入则不然,时间复杂度是O(n/2)。
我们看看代码来验证一下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
public void add(int index, E element) {
checkPositionIndex(index); //判断index是否在有效范围内
if (index == size) //如果在索引等于长度则直接尾插入
linkLast(element);
else
linkBefore(element, node(index));
}
void linkBefore(E e, Node<E> succ) {
final Node<E> pred = succ.prev; //获取succ节点的前一个节点,pred
final Node<E> newNode = new Node<>(pred, e, succ); //生成一个新节点,在pred于succ之间
succ.prev = newNode; //将succ前一个节点的引用指向新生成节点newNode
if (pred == null) //如果前一个节点为空,则newNode为第一个节点
first = newNode;
else
pred.next = newNode; //修改pred下一个节点的指针
size++;
modCount++;
}
Node<E> node(int index) {
if (index < (size >> 1)) { // size>>1等于size/2 通过一次二分法来减少次数。
Node<E> x = first; //从头节点开始遍历查找
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last; //从尾节点开始遍历查找
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
指定位置插入这部分做了总结起来做了两件是:
- 找到当前index节点;
- 将新建节点与插入在index节点和index前一个节点之间,并重新同时建立绑定关系;
因此需要遍历找到指定的节点,为了提升效率采用了一次二分法来缩短时间复杂度。不过在size较大的情况所需的时间要需要很多,所以LinkedList面对指定插入的情况都需要谨慎。
删除
删除的流程和插入差不多,只是将绑定的过程改为了解绑
删除也分为头删除,尾删除,指定位置删除。流程一样所以时间复杂度一样。
头删除:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21public E removeFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return unlinkFirst(f);
}
private E unlinkFirst(Node<E> f) {
final E element = f.item; //获取头结点的值,在最后当做结果返回
final Node<E> next = f.next; //获取首个节点后的第二个节点
f.item = null;
f.next = null; //置空首个节点的全部引用,利于GCRoot时回收
first = next; //将第二个节点设置为第一个节点
if (next == null) //如果next为空值,则表明删除完没有节点,则将last节点也置空
last = null;
else
next.prev = null; //将next节点的前引用置空
size--;
modCount++;
return element;
}
以上的代码比较简单,时间复杂度是O(1),最主要的是做了2件事
- 删除first指向的首个节点;
- 将first指针指向第二个节点;
我们来看看尾删除,它也是做了两件事情:
- 删除last指向的最后个节点;
- 将last指针指向倒二节点;
1 | public E removeLast() { |
指定位置的删除也会给人很类似的感觉:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
public E remove(int index) {
checkElementIndex(index);
return unlink(node(index));
}
E unlink(Node<E> x) {
final E element = x.item; //获取指定位置的值,在最后当做结果返回
final Node<E> next = x.next; //获取指定位置的下一个节点
final Node<E> prev = x.prev; //获取指定位置的前一个节点
if (prev == null) { //如果前一个节点为空的话,则说明指定位置为首节点,则将first引用指向下一个节点
first = next;
} else {
prev.next = next; //将前一个节点绑定下一个节点
x.prev = null;
}
if (next == null) { //如果下一个节点为空的话,则说明指定位置为尾节点,则将last引用指向前一个节点
last = prev;
} else {
next.prev = prev; //将下一个节点绑定上一个节点
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}
Node<E> node(int index) {
if (index < (size >> 1)) { // size>>1等于size/2 通过一次二分法来减少次数。
Node<E> x = first; //从头节点开始遍历查找
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last; //从尾节点开始遍历查找
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
以上的代码做了两件事:
- 找到当前index节点;
- 将要删除的index节点的上一个节点和下一个节点之间,并重新同时建立绑定关系;
因为要查找要删除的节点,所以时间复杂度是O(n/2)。
查询
查询这部分代码,我们很熟悉,就是通过node方法来查找节点。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
Node<E> node(int index) {
if (index < (size >> 1)) { // size>>1等于size/2 通过一次二分法来减少次数。
Node<E> x = first; //从头节点开始遍历查找
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last; //从尾节点开始遍历查找
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
现在为了优化采用了一次2分法,个人感觉后期应该会加入多次2分发的方式来继续提升效率。
序列化
正常情况下,我们使用序列化,都不需要重写以下方法(writeObject/readObject),这两个方法的作用是用来指定序列化过程中,如何写入与读取值的。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21 private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException {
s.defaultWriteObject();
s.writeInt(size);
for (Node<E> x = first; x != null; x = x.next) //从头循环遍历链表,写入输出流
s.writeObject(x.item);
}
private void readObject(java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException {
s.defaultReadObject();
int size = s.readInt();
for (int i = 0; i < size; i++) //循环遍历链表,按照从头插入
linkLast((E)s.readObject());
}
这段代码很简单。就是重写了wirteObject与readObject。但是我这里有一个疑问
为什么不使用默认的wirteObject与readObject,而重写他们呢?
和其他的容器不一样,这里这样做的原因是LinkedList本身没有一个底层数据结构,而是通过头节点和尾节点建立整个链路的关系,因此在序列化的时候要通过整条链路的关系复写写入和读取序列化。
浅拷贝
LinkedList实现了clone方法,从拷贝的维度上区分,LinkedList为浅拷贝,为什么LinkedList是浅拷贝呢?我们贴出以下源码1
2
3
4
5
6
7
8
9
10
11
12public Object clone() {
LinkedList<E> clone = superClone();
clone.first = clone.last = null;
clone.size = 0;
clone.modCount = 0;
for (Node<E> x = first; x != null; x = x.next)
clone.add(x.item);
return clone;
}
以上代码做了两件事情
- 通过clone方法生成新的LinkedList,复制了其中的基础类型
- 复制了原链表中的元素引用
区分浅拷贝和深拷贝的一个很重要的标准是:拷贝对象的元素和原对象的元素是否相同。如果相同则为浅拷贝,不相同为深拷贝
因此虽然生成了新的LinkedList,可是其内的数组对象引用还是与原对象相同。因此是浅拷贝无疑了。
fast-fail
fast-fail 的主要作用是用来校验在某些操作(常为多线程操作)的过程中,元素是否被修改,如果被修改就报ConcurrentModificationException的错误。在LinkedList或其他容器中 一般实现是由expectedModCount 与 modCount 进行对比,来保证元素没有被操作过。
就这部分的内容,是具有通用性的,在java.util中被广泛使用,如HashMap等。我将另开章节fast-fail机制来绍
总结
LinkedList 经常与ArrayList作为对比,两者最大的差异来源于底层的数据结构。在插入方面,如果遇到ArrayList扩容,LinkedList的效率应该是远优于ArrayList插入的。而在删除方面,除了删除尾元素之外,LinkedList效率也优于ArrayList,因此Arraylist再以上的情况下,都要进行数组拷贝。而在访问方面则是ArrayList则是非常快的。因此我们可以总结一下:
新增与删除较多的场景,使用LinkedList;而访问场景多的情况,使用ArrayList。
对比着看两个容器的源码,有助于大家加深对2者的印象。