
前言
为了方便追小说更新撸了一个基于scrapy的爬虫。在实现过程中使用到了 yield,网上对其的文字描述都很难让人理解。通过Debug代码才了解调用顺序,进而理解了它使用方法。
概念
理解yield作用
我们可以用一个等式来形容其作用:
yeild 函数 = return 生成器(generator)
什么是生成器
生成器 = 可迭代的函数
正常情况下我们可以这样迭代一个列表1
2
3
4
5
6
7
8
9# encoding:UTF-8
def call(i):
return i * 2
array = [call(0),call(1),call(2)]
for i in array:
print(i, ",")
打印结果:1
2
30 ,
2 ,
4 ,
以上的代码,适合在数据量小的情况下运行,假如在海量数据的场景下,这样的写法将对内存造成很大的压力。因为列表内所有数据都同时加载在内存中。
而python的生成器则完美的解决了这一问题,它不需要将所有的值同时加载, 它只提供了一个生成数据的方式, 而且它是可迭代
1 | # encoding:UTF-8 |
打印结果:1
2
30 ,
2 ,
4 ,
可以看到 generator 做的事情很简单:循环生成了0到2相对应的值。而yield的作用就是提供生成器给外部。
这样做的好处就在于每次值都是按需生成的,且生成完不会停驻在内存中。
调用顺序
值得一提的就是yield的调用顺序也是很清奇的,它的调用顺序和不是简单的自上而下。
我们在以上的demo中加入几行print1
2
3
4
5
6
7
8
9
10
11
12
13# encoding:UTF-8
def call(i):
return i * 2
def generator(n):
for i in range(n):
yield call(i)
print("generate i=", i)
print("end.")
for i in generator(3):
print(i, ",")
在我们的预期中,我们的预期执行顺序是
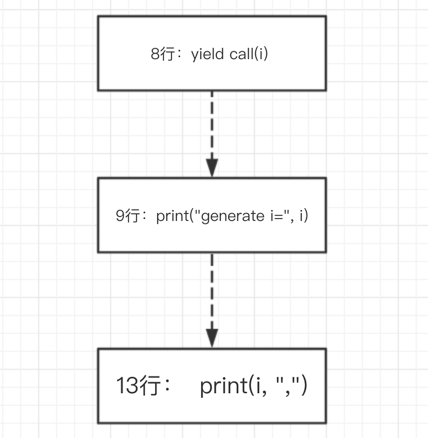
1
2
3
4
5
6
7generate i= 0
0 ,
generate i= 1
2 ,
generate i= 2
4 ,
end.
而它的结果运行结果却是这样:
1 | 0 , |
那么意味着它的执行顺序是这样: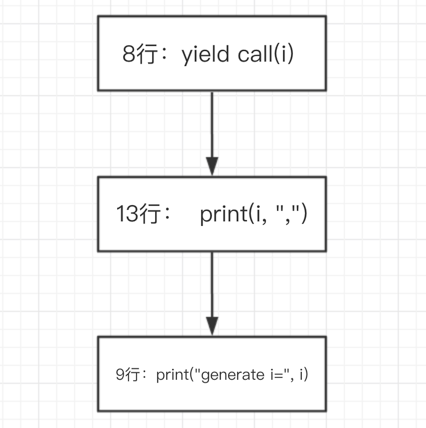
debug后也发现的确如此。
可以发现,只要执行到yield关键字都会先return,在外层执行完毕后,再执行yield之后下一条指令。
启发
当我们处理数据量大的事物的时候,可以效仿关键字yield这样的思路:持有索引或者其他可检索的id,在需要的时候再去通过构造器或者其他工具获取