
前言
看小说是我这么多年来一直保持的习惯。《盘龙》、《斗破苍穹》、《仙逆》、《凡人修仙传》等等,陪伴了我整个学生时代。最近发现iOS上小说类app体验都不好,经常出现广告弹出、更新不及时、强制分享等情况。于是在一个下雨的晚上,我决定不再忍受这些app,自己强撸一个追书爬虫。
Scrapy介绍
Scrapy是python主流爬虫框架,可以很方便的通过url抓取web信息,同时与传统的requests库相比,提供了更多的工具和更高的并发。推荐从官方学习网站上学习。
不过,你一点scrapy资料都不知道也没有关系,读完本文一样能撸出来
Scrapy实战
在开始前,我们需要准备好以下几个东西:
- 想要爬取的小说url
- 环境搭建
- 入门级的python语法
选取网站
这里我选的是 https://m.book9.net/。 选这个网站是因为它有是三个优点
- 更新速度比较快 (服务稳定)
- 页面的结构简单 (易于解析)
- 没有做一些防爬虫的保护 (操作简单)
接下来,找到追更小说的主页。
比如 辰东的《圣墟》

假设现在我们要追更的话,需要每次打开这个网站,然后点击最新章节的第一个选项条,链接到具体的小说章节。
仿造以上的步骤,我画出了这样一个流程:
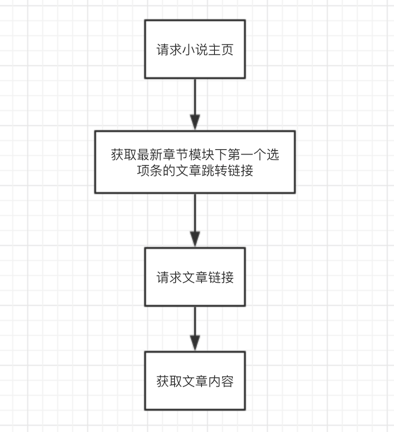
所以接下来,我们只需要根据这些流程来转化成我们的代码就好了
搭建工程
我们将要搭建一个Scrapy壳工程,在这之前要先确保自己安装了python的环境。框架自身兼容2、3版本,所以不需要担心版本的差异。
我本地的环境是python3,所以可能会和2有细微的差异操作。
1.安装Scrapy1
pip3 install scrapy
2.创建爬虫工程,将其命名为NovelCrawler1
scrapy startproject NovelCrawler
3. 创建一个基于 url 的爬虫服务1
scrapy genspider novel m.book9.net
以上就是基本的工程创建过程,执行完毕之后就可以使用1
scrapy crawl novel
命令去开启爬虫服务。不过当前我们的爬虫还没有实现任何的规则,所以即使执行了命令也不会做任何事,所以我们需要在工程中添加一些爬虫规则。
爬虫编写
接下来我们用Pycharm来打开刚刚创建好的工程。
scrapy的所有爬虫服务都集中在spiders目录下,我们也在这里添爬虫文件novel.py
请求小说主页
我们打开文件,添加一些基础的配置
1 | # encoding:utf-8 |
上面的代码中,parse函数的入参数response对象里面有什么参数对我们来说是未知的,这也是初学python很头疼的地方。这里给大家提供一个方法:用Pycharm的debug功能查看参数
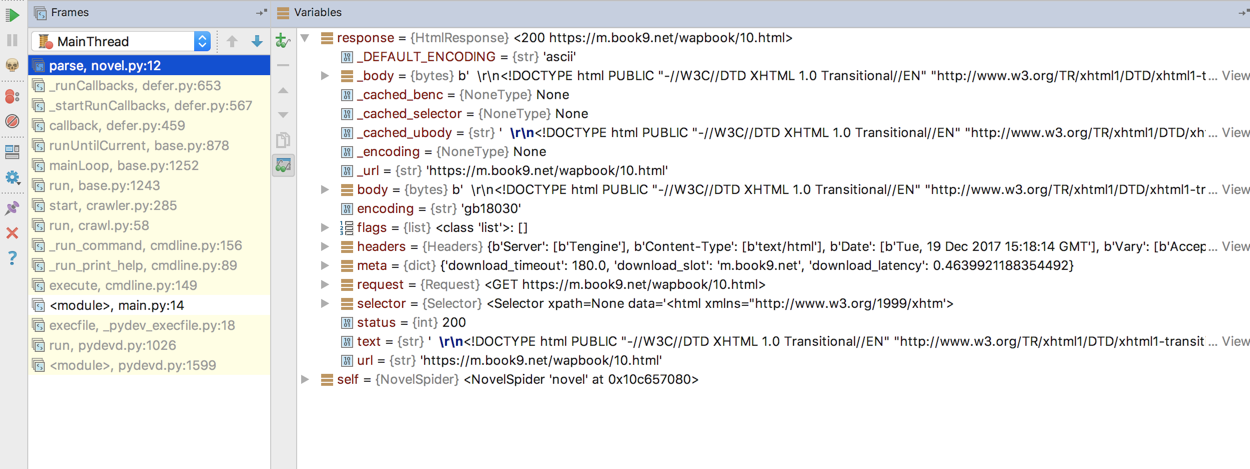
从上图中我们可以发现,response包含了请求的html信息。因此我们只需要其稍加处理,截取出我们需要的部分。
获取最新章节url
那么如何解析我们需要的节点呢,response给我们提供了
xpath方法,我们只需要输入的xpath规则就可以定位到相应html标签节点。
不会xpath语法没关系,Chrome给我们提供了一键获取xpath地址的方法(右键->检查->copy->copy xpath),如下图: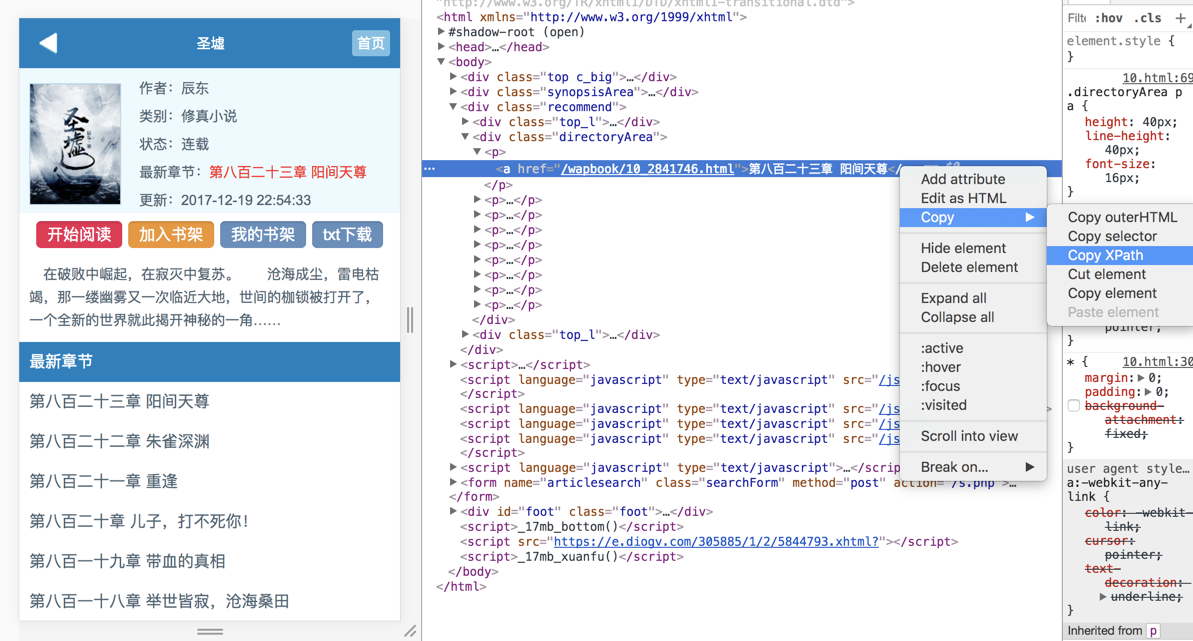
通过xpath,我们可以从这个页面获取到最新章节的地址
1 | # encoding:utf-8 |
请求章节信息
有了链接之后,我们就可以跳转到下一个页面。而response也提供了follow方法,便于我们在站内进行短链的跳转。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20# encoding:utf-8
import scrapy
class NovelSpider(scrapy.Spider):
name = 'novel'
allowed_domains = ['m.book9.net']
start_urls = ['https://m.book9.net/wapbook/10.html']
def parse(self, response):
context = response.xpath('/html/body/div[3]/div[2]/p[1]/a/@href')
url = context.extract_first()
#获取短链后继续请求,并将结果返回指定的回调
yield response.follow(url=url, callback=self.parse_article)
#自定义回调方法
def parse_article(self,response):
#这里的response 就是我们具体的文章页
print(response)
pass
(如对代码中关键字yield感到疑惑的请点击传送门)
有了文章的页面,我们只需要对他的html进行解析。这部分内容过于面向细节。只适用于这个网站,因此我不过多进行赘述。附上注释代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52# encoding:utf-8
import re
import os
import scrapy
class NovelSpider(scrapy.Spider):
name = 'novel'
allowed_domains = ['m.book9.net']
start_urls = ['https://m.book9.net/wapbook/10.html']
def parse(self, response):
# 指定的<a>标签的跳转链接
context = response.xpath('/html/body/div[3]/div[2]/p[1]/a/@href')
#获取短链后继续请求,并将结果返回指定的回调
url = context.extract_first()
yield response.follow(url=url, callback=self.parse_article)
def parse_article(self, response):
#获取文章的标题
title = self.generate_title(response)
#构建文章的html
html = self.build_article_html(title, response)
#将章节html存至本地
self.save_file(title + ".html", html)
#用自带的浏览器打开本地html
os.system("open " + title.replace(" ", "\ ") + ".html")
pass
def build_article_html(title, response):
#获取文章内容
context = response.xpath('//*[@id="chaptercontent"]').extract_first()
#过略文章中<a> 标签跳转内容
re_c = re.compile('<\s*a[^>]*>[^<]*<\s*/\s*a\s*>')
article = re_c.sub("", context)
#拼接文章html
html = '<html><meta http-equiv="Content-Type" content="text/html; charset=utf-8" /><div align="center" style="width:100%;text-alight:center"><b><font size="5">' \
+ title + '</font></b></div>' + article + "</html>"
return html
def generate_title(response):
title = response.xpath('//*[@id="read"]/div[1]/text()').extract()
return "".join(title).strip()
def save_file(file_name, context):
fh = open(file_name, 'wb')
fh.write(context.encode(encoding="utf-8"))
fh.close()
pass
现在我们可在再当前目录下运行以下命令:1
scrapy crawl novel
展示视频

思考
整体写完下来,发现很难做到一份代码适用于多个站点。因此遇到在多站点抓取的需求时,为每个站点建立一个爬虫文件会更为适合。